00:00:00
Go Pprof 性能分析工具
在 Go 语言开发中,性能问题往往是项目上线后最棘手的挑战之一。无论是 CPU 占用过高、内存泄漏,还是 goroutine 失控,都可能导致服务响应缓慢甚至崩溃。而 pprof作为 Go 官方提供的性能分析工具,就像一把精准的手术刀,能帮助我们快速定位这些隐藏的性能瓶颈。本文将从基础到实战,全方位讲解 pprof的使用方法,让每个开发同学都能轻松掌握这一必备技能。
整个分析的过程分为两步:1. 导出数据,2. 分析数据。
导出数据
pprof支持多种性能维度的分析,不同类型的分析适用于不同的场景,我们先来认识一下最常用的几种:
| 类型 | 核心含义 | 典型应用场景 |
|---|---|---|
| allocs | 查看过去所有内存分配的样本(历史累计) | 定位内存泄漏、不合理的大内存分配 |
| block | 跟踪阻塞操作(如锁等待、channel 阻塞)(历史累计) | 分析同步操作导致的性能损耗 |
| cmdline | 当前程序的命令行的完整调用路径(从程序一开始运行时决定) | 查看程序启动时的参数配置 |
| goroutine | 记录当前所有 goroutine 的调用栈信息 | 发现 goroutine 泄漏、阻塞问题 |
| heap | 查看活动对象的内存分配情况(实时变化) | 定位内存泄漏、不合理的大内存分配 |
| mutex | 查看导致互斥锁的竞争持有者的堆栈跟踪(历史累计) | 找出锁竞争频繁的代码段 |
| profile | 默认进行 30s 的 CPU Profiling,得到一个分析用的 profile 文件(从开始分析,到分析结束) | 排查 CPU 使用率过高、计算密集型瓶颈 |
| threadcreate | 线程创建相关的采样数据 | 解决线程创建过多的问题 |
| trace | 深入浅出 Go trace | 了解一个耗时程序的行为,并且想知道当每个goroutine不运行时它在做什么 |
注意,默认情况下是不追踪block和mutex的信息的,如果想要看这两个信息,需要在代码中加上两行:
go
runtime.SetBlockProfileRate(1) // 开启对阻塞操作的跟踪,block
runtime.SetMutexProfileFraction(1) // 开启对锁调用的跟踪,mutexWeb
对于长期运行的服务(如 Web 服务、后台 daemon),通过 HTTP 接口暴露pprof数据是最方便的方式。这种方式可以动态采集性能数据,无需重启服务。
实现步骤非常简单:
- 导入必要的包:只需在代码中导入net/http/pprof包,它会自动注册相关的 HTTP 路由,无需额外调用函数。
go
import (
"net/http"
_ "net/http/pprof" // 下划线导入,默默完成路由注册
)- 启动 HTTP 服务:在程序中启动一个 HTTP 服务,pprof会默认使用/debug/pprof路径。通常我们会单独开一个 goroutine 来运行这个服务,避免影响主业务逻辑。
go
func main() {
// 启动HTTP服务,监听6060端口
go func() {
_ = http.ListenAndServe("localhost:6060", nil)
}()
// 这里是你的业务逻辑代码
select {} // 保持主goroutine不退出
}验证是否生效:程序启动后,访问 http://localhost:6060/debug/pprof,如果能看到各种 profile 类型的列表,就说明集成成功了。
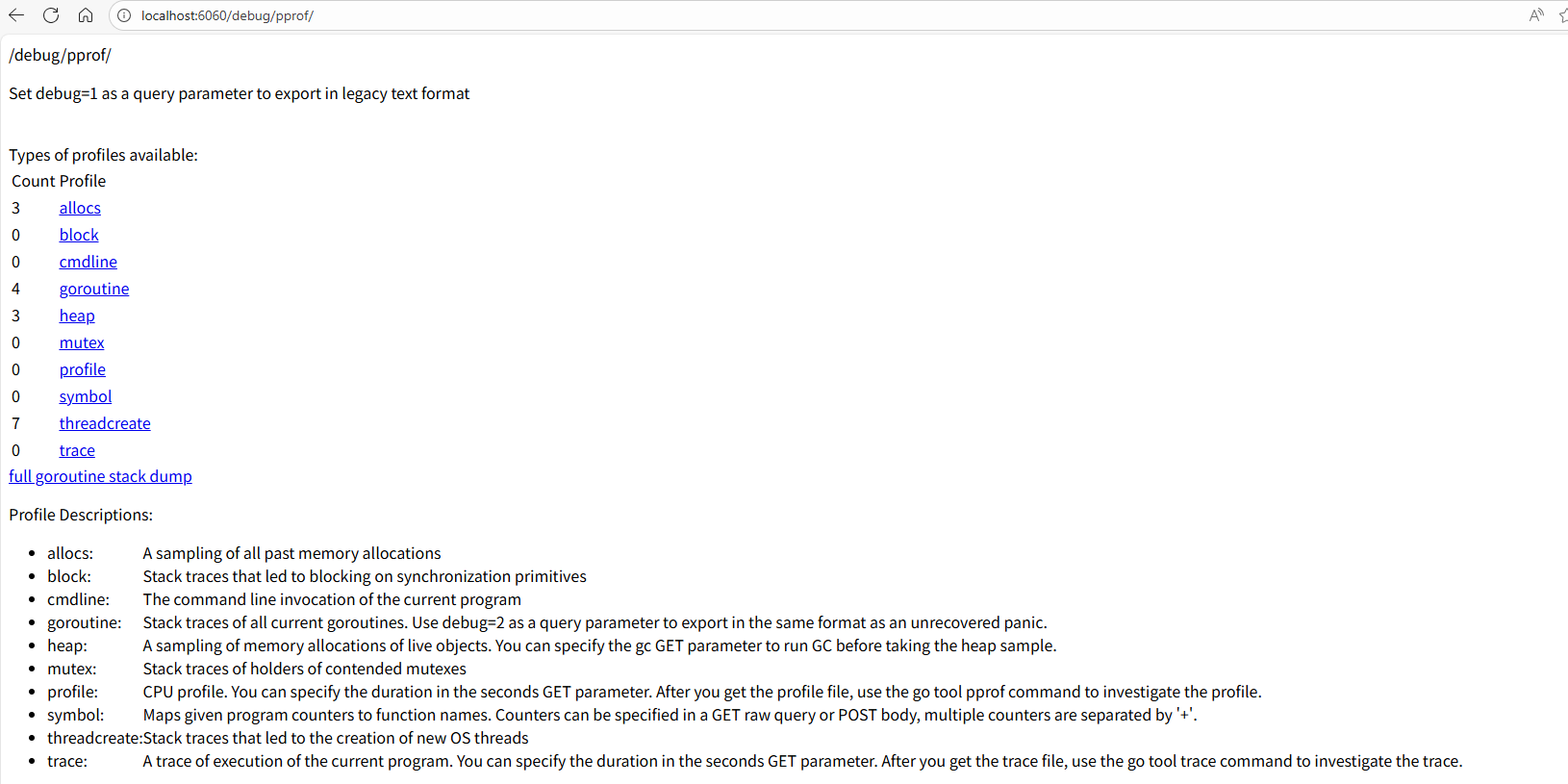
上文的所有信息都是实时的,如果你刷新一下,是可以看到数字在变化的。此时如果点击蓝色的连接,可以看到一些协程的栈信息,这些信息并不容易阅读。如果想要更加清晰的数据,需要将信息保存下来,在本地进行分析。
这里有一个小点要注意,在这个页面下,点击profile和trace总是会下载文件。而点击其他链接会跳转到另一个页面,来展示一些数据,但是可读性也比较差。
如果点击profile,程序会开始进行半分钟(默认值)的CPU采样,然后才会下载文件。
总之,目前这个页面最有用的数据就是直接看看协程数,看看同步数,看看堆和线程创建数。点进去的链接基本都没太强的可读性。操作到这里,能看到这个网页即可。
有了 profile 数据后,接下来就是使用go tool pprof工具进行分析。这个工具功能强大,掌握它的使用方法是定位性能问题的关键。
pprof 基本使用
go tool pprof的命令格式如下:
shell
go tool pprof [options] [binary] [profile]其中,profile来源可以是本地的 profile 文件(如cpu.pprof),也可以是 HTTP 接口(如http://localhost:6060/debug/pprof/cpu?seconds=30,表示采集 30 秒的 CPU 数据)。
常用的选项有:
- inuse_space:查看当前正在使用的内存量(堆内存)
- alloc_space:查看程序运行过程中累计分配的内存量
- seconds N:指定采集数据的时长(仅对 HTTP 来源有效)
直接运行 go tool pprof http://localhost:6060/debug/pprof/XXX,其会自动下载数据到本地,然后供你分析。然而这种方式通常只能支持一次分析,如果未来想回头分析数据,则这种方式不是很推荐。
你可以添加一些参数,来辅助你直接分析数据,需要注意,参数都需要在url之前。
-seconds=30 采样30s,也可以自定义时间范围。需要注意的是,对于profile而言,总是需要采样一段时间,才可以看到数据。而其他历史累计的数据,则可以直接获取从程序开始运行到现在累积的数据,也可以设置-seconds来获取一段时间内的累计数据。而其他实时变化的指标,设置这个参数没什么用,只会让你多等一会。
例如,要采集 30 秒的 CPU 数据并进行分析,可以执行:
shell
go tool pprof -seconds=5 http://localhost:6060/debug/pprof/mutex在运行完这个命令,下载好数据之后,会直接进入和pprof的交互式命令行。
在交互模式中,这些命令能帮助我们快速找到性能瓶颈:
top N:显示前 N 个性能消耗最高的函数。比如top 5会列出 CPU 耗时最多的 5 个函数,这是最常用的命令之一,能让我们快速锁定重点怀疑对象。list 函数名:查看指定函数的代码,并显示每行代码的性能数据。这个命令能帮我们定位到函数内部具体哪一行代码消耗了大量资源。web:生成可视化的调用关系图。这个命令需要系统安装graphviz工具(安装方法见后文),生成的图会用不同颜色和宽度表示函数的性能消耗,非常直观。peek 函数名:查看指定函数的调用者和被调用者的性能数据,帮助我们理解函数在整个调用链中的位置和影响。traces:显示所有函数的调用栈及对应的性能数据,适合分析复杂的调用关系。quit/exit:退出交互模式。
掌握这些命令,就能应对大多数性能分析场景了。
pprof 推荐使用方式
执行 curl -o XXX-X.out http://localhost:6060/debug/pprof/XXX,会下载原始数据到 XXX-X.out 文件。
shell
# curl -o heap.out http://localhost:6060/debug/pprof/heap
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1786 100 1786 0 0 176k 0 --:--:-- --:--:-- --:--:-- 1744k对于那些需要累计一些时间才能采集的指标,我们可以使用?seconds=X来设置。
shell
# curl -o heap.out http://localhost:6060/debug/pprof/heap?seconds=30
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1786 100 1786 0 0 176k 0 --:--:-- --:--:-- --:--:-- 1744k这样,我们就拥有了原始的数据文件,未来可以反复分析,而不用担心原始的数据文件找不到了。
然后我们运行 go tool pprof XXX-X.out,就可以进入pprof命令行交互页面。
test
编写一个test程序,可以更加精准地进行测试。同时一起把性能表现看了,棒!
和网页导出一样,test导出也拥有多个指标的查看方式,具体查看哪些指标,通过命令行的参数来配置。由于go test相比网页,更加定向,因此可以方便地来查看一些数据。这也一并列在这里。
shell
-bench=.
进行性能测试,“.”是正则匹配,匹配了所有的测试函数
-benchmem
打印出申请内存的次数。一般用于简单的性能测试,不会导出数据文件。
-blockprofile block.out
将协程的阻塞数据写入特定的文件(block.out)。如果-c,则写成二进制文件。
-cpuprofile cpu.out
将协程的CPU使用数据写入特定的文件(cpu.out)。如果-c,则写成二进制文件。
-memprofile mem.out
将协程的内存申请数据写入特定的文件(mem.out)。如果-c,则写成二进制文件。
-mutexprofile mutex.out
将协程的互斥数据写入特定的文件(mutex.out)。如果-c,则写成二进制文件。
-trace trace.out
将执行调用链写入特定文件(trace.out)。可以看到,go test会把数据导出在特定的文件之中。之后分析数据就需要读取这些数据。
和网页相似,这些数据本身的可读性很差,还是需要借助go tool pprof来分析。
代码
我们还可以在代码里主动把原始数据写到固定的文件里。代码很简单,主要分为两类,CPU的profile和其他。CPU的采样总是麻烦一些:
go
// 省略了错误处理,仅表达基本的含义
go func() {
f, _ := os.Create("cpu.pprof")
defer f.Close()
_ = pprof.StartCPUProfile(f)
time.Sleep(1 * time.Minute)
pprof.StopCPUProfile()
}()其他的,包括alloc、heap、mutex、block、goroutine、threadcreate,写法上都是一样的,只需要替换那个字符串就行了。
go
// 省略了错误处理,仅表达基本的含义
go func() {
f, _ := os.Create("XXX.pprof")
defer f.Close()
_ = pprof.Lookup("allocs").WriteTo(f, 0) // 前面这个字符串
}()分析数据
shell
# 网页,运行该命令让程序开始半分钟(默认值)的CPU采样
$ go tool pprof http://localhost:6060/debug/pprof/profile
# 看输出的红字,会把文件保存到某一个地址shell
# 文件
$ go tool pprof cpu.out
# 或者
$ go tool pprof pprof.XXX.samples.cpu.001.pb.gz运行上面任一一个命令之后,pprof会等待我们进一步的指示,我们来运行一下help看一看
shell
(pprof) help
Commands:
callgrind Outputs a graph in callgrind format
...... 省略 n 个命令参数很多,但是我们常用的很少。我个人常用的只有两个,top和web。分别对应来文本分析和图分析。
文本分析
top默认按flat排序,打印出消耗前10的函数。也可以选择消耗前N的函数,比如top5,top20。
其中一共有五个指标。这些指标的含义见下文“理解指标”。
shell
(pprof) top
Showing nodes accounting for 69.80s, 50.30% of 138.77s total
Dropped 995 nodes (cum <= 0.69s)
Showing top 10 nodes out of 133
flat flat% sum% cum cum%
19.83s 14.29% 14.29% 60.39s 43.52% runtime.mallocgc
10.03s 7.23% 21.52% 10.66s 7.68% runtime.heapBitsForAddr (inline)
7.22s 5.20% 26.72% 7.22s 5.20% runtime.nextFreeFast
6.28s 4.53% 31.25% 16.84s 12.14% runtime.heapBitsSetType
5.71s 4.11% 35.36% 6.75s 4.86% runtime.(*itabTableType).find
5.47s 3.94% 39.30% 10.19s 7.34% context.(*valueCtx).Value
4.24s 3.06% 42.36% 21.78s 15.70% errors.Is
3.90s 2.81% 45.17% 16.37s 11.80% runtime.gcDrain
3.71s 2.67% 47.84% 10.46s 7.54% runtime.getitab
3.41s 2.46% 50.30% 7.30s 5.26% runtime.scanobject图片一
要看图片,要先安装 graphviz。
web 将会生成一张svg格式的图片,并用默认打开程序打开(一般是游览器)。
图片二(推荐)
另一种更加简便的看图的方式,运行如下命令
shell
go tool pprof -http=:8000 http://localhost:6060/debug/pprof/profile
go tool pprof -http=:8000 cpu.out
go tool pprof -http=:8000 pprof.XXX.samples.cpu.001.pb.gz这将会启动一个web服务器,并自动打开一个网页。这个网页最上方有一个header,我们可以切换到火焰图、top、连线图。
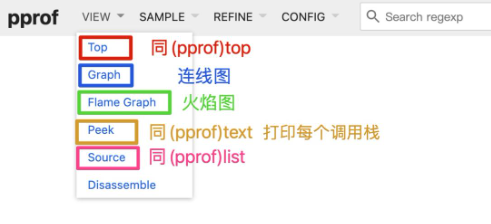
如果是内存信息SAMPLE这一栏有四个选项
- alloc_objects:已分配的对象总量(不管是否已释放)
- alloc_space:已分配的内存总量(不管是否已释放)
- inuse_objects: 已分配但尚未释放的对象数量
- inuse_sapce:已分配但尚未释放的内存数量
怎么看图,见下文“理解指标”、“理解连线图”、“理解火焰图”
理解指标
这一部分很重要!图中的参数也不会超过下面介绍的这些,只是调用关系更加清晰一点。
flat flat%
一个函数内的directly操作的物理耗时。例如
go
func foo(){
a() // step1
largeArray := [math.MaxInt64]int64{} // step2
for i := 0; i < math.MaxInt64; i++ { // step3
c() // step4
}
}flat只会记录step2和step3的时间;flat%即是flat/总运行时间。内存等参数同理。
所有的flat相加即是总采样时间,所有的flat%相加应该等于100%。
flat一般是我们最关注的。其代表一个函数可能非常耗时,或者调用了非常多次,或者两者兼而有之,从而导致这个函数消耗了最多的时间。
如果是我们自己编写的代码,则很可能有一些无脑for循环、复杂的计算、字符串操作、频繁申请内存等等。
如果是第三方库的代码,则很可能我们过于频繁地调用了这些第三方库,或者以不正确的方式使用了这些第三方库。
cum cum%
相比flat,cum则是这个函数内所有操作的物理耗时,比如包括了上述的step1、2、3、4。
cum%即是cum的时间/总运行时间。内存等参数同理。
一般cum是我们次关注的,且需要结合flat来看。flat可以让我们知道哪个函数耗时多,而cum可以帮助我们找到是哪些函数调用了这些耗时的(flat值大的)函数。
sum%
其上所有行的flat%的累加。可以视为,这一行及其以上行,其所有的directly操作一共占了多少物理时间。
理解连线图
每个节点的信息包括了包名、函数名、flat、flat%、cum、cum%
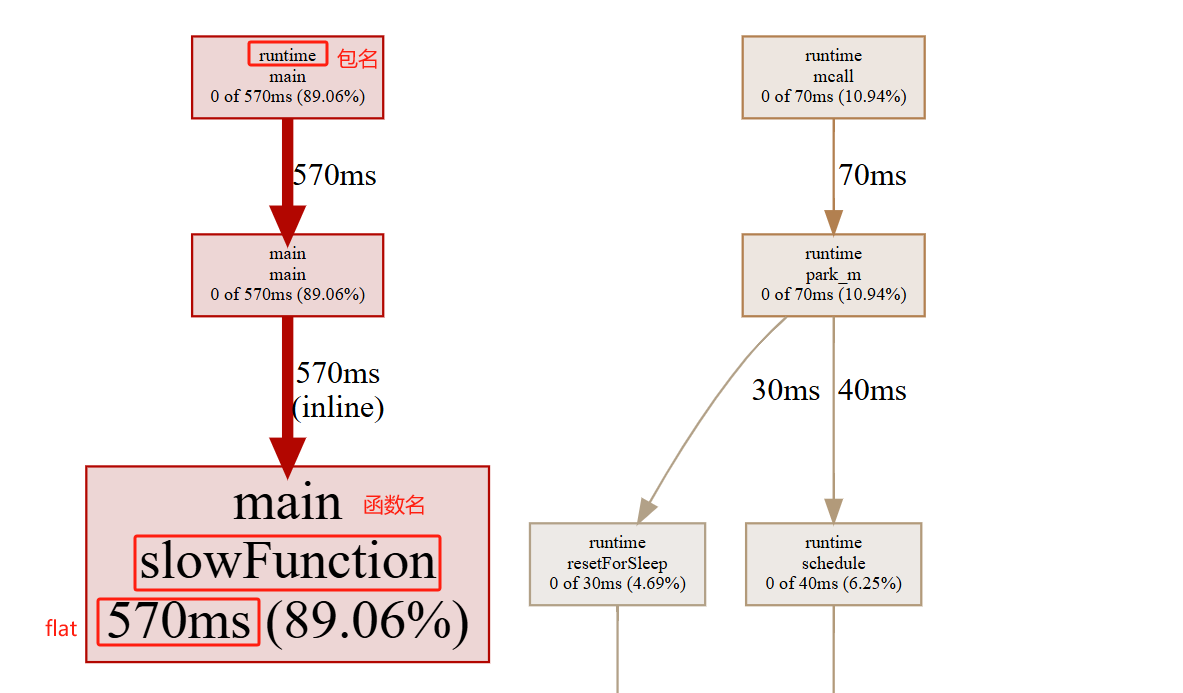
节点的颜色越红,其cum和cum%越大。其颜色越灰白,则cum和cum%越小。
节点越大,其flat和flat%越大;其越小,则flat和flat%越小
线条代表了函数的调用链,线条越粗,代表指向的函数消耗了越多的资源。反之亦然。
线条的样式代表了调用关系。实线代表直接调用;虚线代表中间少了几个节点;带有inline字段表示该函数被内联进了调用方(不用在意,可以理解成实线)。
对于一些代码行比较少的函数,编译器倾向于将它们在编译期展开从而消除函数调用,这种行为就是内联。
理解火焰图
火焰图的横向长度表示cum,相比下面超出的一截代表flat。

火焰图可以进行点击。
实战演练:解决三大典型性能问题
理论讲得再多,不如实际动手操作一遍。下面通过三个典型的性能问题场景,带大家完整体验pprof的实战流程。
场景一:CPU 占用过高,程序运行缓慢
问题描述:一个程序运行起来后,CPU 使用率居高不下,响应速度很慢,怀疑存在 CPU 密集型的性能瓶颈。
步骤 1:准备有问题的代码
我们先写一段有明显 CPU 问题的代码:
go
package main
import (
"net/http"
_ "net/http/pprof"
"time"
)
func main() {
// 启动HTTP服务,方便采集数据
go func() {
http.ListenAndServe("localhost:6060", nil)
}()
// 持续调用一个低效函数
for {
slowFunction()
time.Sleep(100 * time.Millisecond)
}
}
// 低效函数:包含冗余计算
func slowFunction() {
sum := 0
for i := 0; i < 1e7; i++ { // 循环次数过多,消耗大量CPU
sum += i
}
}步骤 2:采集 CPU 数据
运行程序后,执行以下命令采集 30 秒的 CPU 数据:
shell
go tool pprof http://localhost:6060/debug/pprof/profile?seconds=30等待 30秒后,工具会进入交互模式。
步骤 3:分析并定位问题
在交互模式中执行top 5,查看 CPU 消耗最高的函数:
shell
go tool pprof http://localhost:6060/debug/pprof/profile?seconds=30
Fetching profile over HTTP from http://localhost:6060/debug/pprof/profile?seconds=30
Saved profile in /home/murphy/pprof/pprof.main.samples.cpu.003.pb.gz
File: main
Build ID: 4ebd917705354de22fe3b74d3e18914f4afb0bc4
Type: cpu
Time: 2025-11-03 14:50:17 CST
Duration: 30s, Total samples = 800ms ( 2.67%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top 5
Showing nodes accounting for 800ms, 100% of 800ms total
Showing top 5 nodes out of 19
flat flat% sum% cum cum%
760ms 95.00% 95.00% 760ms 95.00% main.slowFunction (inline)
20ms 2.50% 97.50% 20ms 2.50% runtime.write1
10ms 1.25% 98.75% 20ms 2.50% runtime.findRunnable
10ms 1.25% 100% 10ms 1.25% runtime.futexsleep
0 0% 100% 760ms 95.00% main.main可以看到,slowFunction函数占用了几乎全部的 CPU 时间,是主要的性能瓶颈。
接着用list slowFunction查看函数内部的代码耗时:
shell
(pprof) list slowFunction
Total: 800ms
ROUTINE ======================== main.slowFunction in /home/murphy/workspace/golang/src/github.com/moweilong/blog-go-example/goroutine/course1/pprof/main.go
760ms 760ms (flat, cum) 95.00% of Total
. . 23:func slowFunction() {
. . 24: sum := 0
760ms 760ms 25: for i := 0; i < 1e7; i++ { // 循环次数过多,消耗大量CPU
. . 26: sum += i
. . 27: }
. . 28:}很明显,第 25 行的循环是罪魁祸首,循环次数过多导致 CPU 占用过高。
场景二:内存占用持续上升,疑似内存泄漏
问题描述:程序运行一段时间后,内存占用越来越高,而且不会释放,可能存在内存泄漏。
步骤 1:准备有内存泄漏的代码
go
package main
import (
"net/http"
_ "net/http/pprof"
"time"
)
var globalSlice []int // 全局切片,不断积累数据导致内存泄漏
func main() {
go func() {
http.ListenAndServe("localhost:6060", nil)
}()
// 持续向全局切片添加数据,不释放
for {
leakMemory()
time.Sleep(100 * time.Millisecond)
}
}
func leakMemory() {
// 每次分配一块内存,添加到全局切片
data := make([]int, 1024*2) // 约8KB
globalSlice = append(globalSlice, data...)
}步骤 2:采集内存数据
执行以下命令采集堆内存数据(查看当前使用的内存):
shell
go tool pprof -inuse_space http://localhost:6060/debug/pprof/heap步骤 3:分析并定位问题
在交互模式中执行top 5:
shell
(pprof) top 5
Showing nodes accounting for 39373.05kB, 100% of 39373.05kB total
Showing top 5 nodes out of 19
flat flat% sum% cum cum%
36296kB 92.18% 92.18% 36296kB 92.18% main.leakMemory (inline)
2565kB 6.51% 98.70% 2565kB 6.51% runtime.allocm
512.05kB 1.30% 100% 512.05kB 1.30% runtime.acquireSudog
0 0% 100% 36296kB 92.18% main.main
0 0% 100% 512.05kB 1.30% runtime.gcBgMarkWorker可以看到,leakMemory函数占用了几乎全部的内存,是主要的内存泄漏问题。
接着用list leakMemory查看函数内部的代码:
shell
(pprof) list leakMemory
Total: 38.45MB
ROUTINE ======================== main.leakMemory in /home/murphy/workspace/golang/src/github.com/moweilong/blog-go-example/goroutine/course1/pprof/memory/main.go
35.45MB 35.45MB (flat, cum) 92.18% of Total
. . 23:func leakMemory() {
. . 24: // 每次分配一块内存,添加到全局切片
. . 25: data := make([]int, 1024*2) // 约8KB
35.45MB 35.45MB 26: globalSlice = append(globalSlice, data...)
. . 27:}优化方案
避免无限制地向全局变量添加数据,对于不再使用的数据及时从切片中移除,或者使用有界的容器来存储数据。
场景三:goroutine 数量暴增,资源耗尽
问题描述:程序运行一段时间后,goroutine 的数量越来越多,最终导致系统资源耗尽,可能存在 goroutine 泄漏。
步骤 1:准备有 goroutine 泄漏的代码
go
package main
import (
"net/http"
_ "net/http/pprof"
"time"
)
func main() {
go func() {
http.ListenAndServe("localhost:6060", nil)
}()
// 持续创建goroutine,但这些goroutine不会退出
for {
leakGoroutine()
time.Sleep(100 * time.Millisecond)
}
}
func leakGoroutine() {
ch := make(chan int) // 无缓冲channel
go func() {
<-ch // 等待接收数据,但永远不会有数据发送,导致goroutine阻塞泄漏
}()
}步骤 2:采集 goroutine 数据
执行以下命令采集所有 goroutine 的状态:
shell
go tool pprof http://localhost:6060/debug/pprof/goroutine步骤 3:分析并定位问题
在交互模式中执行traces,查看 goroutine 的调用栈:
shell
(pprof) traces
File: main
Build ID: 17fae42dd3b582d315c9fa4bd2278885f1c83c41
Type: goroutine
Time: 2025-11-03 15:11:00 CST
-----------+-------------------------------------------------------
2319 runtime.gopark
runtime.chanrecv
runtime.chanrecv1
main.leakGoroutine.func1
-----------+-------------------------------------------------------
1 runtime.goroutineProfileWithLabels
runtime.pprof_goroutineProfileWithLabels
runtime/pprof.writeRuntimeProfile
runtime/pprof.writeGoroutine
runtime/pprof.(*Profile).WriteTo
net/http/pprof.handler.ServeHTTP
net/http/pprof.Index
net/http.HandlerFunc.ServeHTTP
net/http.(*ServeMux).ServeHTTP
net/http.serverHandler.ServeHTTP
net/http.(*conn).serve
-----------+-------------------------------------------------------可以看到大量的 goroutine 都阻塞在main.leakGoroutine.func1函数的<-ch语句上,这些 goroutine 永远不会退出,导致数量不断增加,形成泄漏。
优化方案
为 goroutine 设置退出条件,比如使用context.Context来控制超时,或者确保 channel 的发送和接收操作能正常完成,避免无意义的阻塞。
总结与展望
pprof作为 Go 语言性能分析的利器,其核心价值在于帮助我们从纷繁复杂的代码中,精准定位性能瓶颈。掌握它的使用方法,能让我们在面对性能问题时不再束手无策。
回顾一下pprof的使用流程:
- 根据程序类型(服务 / 脚本)选择合适的集成方式(HTTP 接口 / 手动生成文件);
- 针对具体性能问题(CPU / 内存 /goroutine 等),采集对应的 profile 数据;
- 使用go tool pprof工具的top、list、web等命令分析数据,定位问题根源;
- 根据分析结果进行代码优化,并验证优化效果。
当然,pprof的功能远不止本文介绍的这些,还有很多高级用法等待大家去探索。希望通过本文的分享,能让大家在日常开发中更多地运用pprof来提升代码质量,打造高性能的 Go 应用。
最后,建议大家在开发和测试阶段就养成使用pprof的习惯,提前发现并解决性能问题,避免在生产环境中造成损失。让我们一起,写出更高效、更稳定的 Go 代码!